技術介紹
緩存溢出(或譯為緩沖溢出)為黑客最為常用的攻擊手段之一,蠕蟲病毒對操作系統高危漏洞的溢出高速與大規模傳播均是利用此技術。緩存溢出攻擊從理論上來講可以用于攻擊任何有缺陷不完美的程序,包括對殺毒軟件、防火牆等安全産品的攻擊以及對銀行程序的攻擊。
緩存區溢出存在于各種電腦程序中,特别是廣泛存在于用C、C++等這些本身不提供内存越界檢測功能的語言編寫的程序中。C、C++作為程序設計基礎語言的地位還沒發生改變,它們仍然被廣泛應用于操作系統、商業軟件的編寫中,每年都會有很多緩存區溢出漏洞被人們從已發布和還在開發的軟件中發現出來。從CERT漏洞數據庫和國家漏洞數據庫NVD中統計2001—2012年每一年發現的緩存區溢出漏洞數如圖1所示。雖然從圖1上看出緩存區溢出數相比2007年已經大幅減少,但在2011年的CWE/SANS最危險的軟件漏洞排行榜上,“沒進行輸入大小檢測的緩存區複制”漏洞排名第三。可見,如何檢測和預防緩存區溢出漏洞仍然是一個非常棘手的問題。
攻擊方式
為實現緩存區溢出攻擊,攻擊者必須在程序的地址空間裡安排适當的代碼及進行适當的初始化寄存器和内存,讓程序跳轉到入侵者安排的地址空間執行。控制程序轉移到攻擊代碼的方法有如下幾種:
破壞活動記錄
函數調用發生時,調用者會在棧中留下函數的活動記錄,包含當前被調函數的參數、返回地址、前棧指針、變量緩存區等值,它們在棧中的存放順序如圖2所示。由它們在棧中的存放順序可知,返回地址、棧指針與變量緩存區緊鄰,且返回地址指向函數結束後要執行的下一條指令。棧指針指向上一個函數的活動記錄,這樣攻擊者可以利用變量緩存區溢出來修改返回地址值和棧指針,從而改變程序的執行流。
破壞堆數據
程序運行時,用戶用C、C++内存操作庫函數如malloc、free等在堆内存空間分配存儲和釋放删除用戶數據,對内存的使用情況如内存塊的大小、它前後指向的内存塊用一個鍊接類的數據結構予以記錄管理,管理數據同樣存放于堆中,且管理數據與用戶數據是相鄰的。這樣,攻擊者可以像破壞活動記錄一樣來溢出堆内存中分配的用戶數據空間,從而破壞管理數據。因為堆内存數據中沒有指針信息,所以即使破壞了管理數據也不會改變程序的執行流,但它還是會使正常的堆操作出錯,導緻不可預知的結果。
更改函數指針
指針在C、C++等程序語言中使用得非常頻繁,空指針可以指向任何對象的特性使得指針的使用更加靈活,但同時也需要人們對指針的使用更加謹慎小心,特别是空的函數指針,它可以使程序執行轉移到任何地方。攻擊者充分利用了指針的這些特性,千方百計地溢出與指針相鄰的變量、緩存區,從而修改函數指針指向達到轉移程序執行流的目的。溢出的具體方法可以參考文獻,本文不再詳述。
溢出固定緩存區
C标準庫函數中提供了一對長跳轉函數setjmp/longjmp來進行程序執行流的非局部跳轉,意思是在某一個檢查點設置setjmp(buffer),在程序執行過程中用longjmp(buffer)使程序執行流跳到先前設置的檢查點。它們跟函數指針有些相似,在給用戶提供了方便性的同時也帶來了安全隐患,攻擊者同樣隻需找一個與longjmp(buffer)相鄰的緩存區并使它溢出,這樣就能跳轉到攻擊者要運行的代碼空間。典型的例子有Perl5.003的緩沖區溢出漏洞,攻擊者首先進入用來恢複緩沖區溢出的longjmp緩沖區,然後誘導進入恢複模式,這樣就使Perl的解釋器跳轉到攻擊代碼上了。
檢測和預防
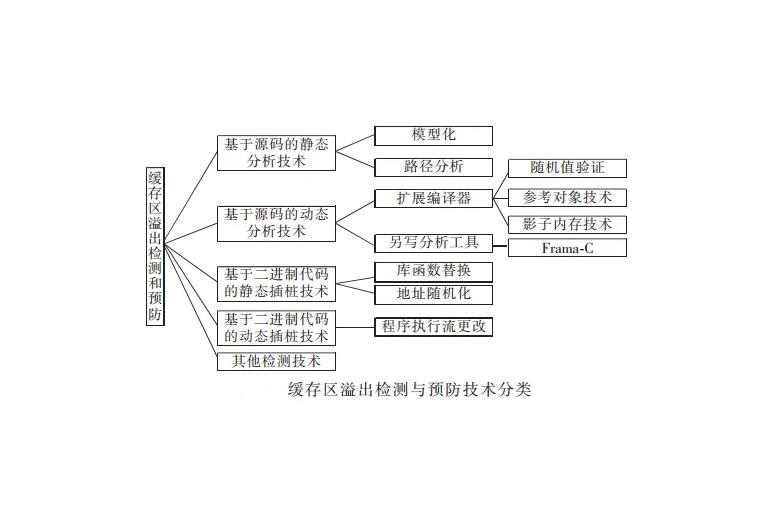
緩存區溢出首次進入公共視野是在1988年的第一種緩存區溢出攻擊---Morris蠕蟲,被羅伯特等人制造出來造成全世界6000多台網絡服務器癱瘓後,人們開始關注緩存區溢出,并相繼提出了各種各樣的緩存區溢出檢測與預防技術和工具。本文參考李毅超、夏一民等人的分類,根據技術是作用于源碼還是二進制代碼、是隻靜态分析代碼還是要重新編譯運行代碼,把所有的緩存區溢出檢測和預防技術進行分類,如圖3所示。随後介紹了主流的檢測和預防技術的原理、發展曆程和優缺點。
基于源碼的靜态分析技術
模型化
模型化方法是靜态分析裡一種常用的方法,它可以用在程序分析的很多方面,如判斷可執行路徑中正确屬性是否發生的nevertrace方法,能以較低花費支持安全需求進化過程的模型監測方法;同時它還能把緩存區的定義與使用信息及其之間的關系與緩存區有關的語句和函數都予以建模,把緩存區溢出檢測問題等價地轉換為模型驗證問題。将緩存區溢出檢測轉換為整數限制求解問題,把C字符串作為一個抽象數據類型,每一個緩存區用兩個整數來描述,一個是整數表示緩存區被分配的大小,另一個表示緩存區使用的當前位置。标準庫函數被模型化為單純的長度賦值語句,判斷每次緩存區操作時緩存區使用的當前位置是否超過它所占内存的範圍,這樣即可把緩存區溢出檢測問題轉換為整數限制求解問題。但由于整數範圍分析得不夠精确,使得該方法存在誤報,且報告緩存區溢出時不能提供導緻該溢出的相關信息,因而人工驗證的成本很高。CodeAuditor是上述技術的另一種實現方式,所不同的是緩存區溢出檢測不再轉換為整數限制求解問題,而是轉換為模型驗證問題。CodeAuditor把與緩存區有關的語句和函數轉換為整數轉移函數和約束(這些函數與約束就是判斷緩存區是否溢出),在源代碼的AST樹上插入函數和約束的驗證語句,用模型驗證方法來判斷這些函數和約束是否能得到滿足。該方法有效地解決了因為範圍分析不夠精确而導緻的誤報率過高問題。從上面分析可知,模型化的方法對模型的質量要求很高,模型不夠全面的話會漏掉很多錯誤;由于是把原問題轉換為其他問題求解,丢失了原來的一些信息,也容易導緻誤報;當産生錯誤報告時不能提供為改正該錯誤有用的信息,因而錯誤修改亦不方便。
路徑分析
路徑分析是根據程序的控制流圖對每條執行路徑進行分析,判斷沿着路徑的執行是否導緻緩存區溢出。對路徑既可以正向遍曆亦可以反向遍曆。正向遍曆是在原程序的緩存區操作前加入檢測語句,程序順序執行并運行檢測語句來判斷緩存區是否溢出;反向遍曆是當遇到一個緩存區操作時,逆向遍曆經過該緩存區的所有路徑,得到緩存區的分配使用信息,比較分配使用值的大小關系即能判斷緩存區是否溢出。SecTAC是一個路徑再測試工具,它重用以前的測試用例來産生執行路徑,每條路徑符号執行後都會生成程序約束和安全約束,當程序變量滿足程序約束但是不滿足安全約束時,錯誤報告就會産生。該方法受産生執行路徑的測試用例的限制,如果測試用例不夠全面,漏報就會很多;當程序大且複雜時,執行路徑太多,SecTACSL的處理時間就會很長。Marple把路徑分為infeasible、safe、vulnerable、overflow-input-independent和don’t-know五類,它首先用分析器分析程序剔除不可能存在緩存區溢出漏洞的路徑,從可能存在緩存區溢出漏洞的語句上提出查詢;然後反向遍曆控制流程圖,并從源碼中提取出緩存區相關信息;再建立漏洞模型來構造、更新、求解該查詢。當遇到進入infeasible路徑塊、收集的信息已夠解決該查詢和到函數入口時查詢還未解決這三種情況時,分析結束。如由收集的信息判斷出現了緩存區溢出,Marple會返回可能導緻産生該溢出的路徑信息。Marple的缺陷是它把很多庫函數調用、循環語句、共享的全局變量等作為don’t-know類型來處理,這樣就漏掉了很多漏洞。除了上面這兩種方法外,還有其他的路徑分析方法,如已有方法把可能導緻緩存區溢出的路徑分為三種模式:語法使用、元素訪問和塊移動。先用語法分析器把所有的語法使用錯誤都剔除,然後用受限的符号評價系統對後兩種模式進行分析,找出存在的緩存區溢出漏洞。該方法對用戶自定義的操作不兼容,因而存在誤報與漏報。雖然路徑分析方法能綜合上下文對緩存區溢出進行檢測,減少了緩存區溢出檢測的誤報率,能對檢測語句進行優化,減少了處理時間,但從上面的叙述可以看出,它存在很明顯的漏報。對于大型的複雜的程序,因為路徑過多,檢測效果就更加不理想了。
基于源碼的動态分析技術
擴展編譯器
1)值驗證
為預防破壞活動記錄的攻擊,可以在返回地址和局部變量之間插入一個固定值,如果緩存區溢出了必然會使該固定值發生改變,在訪問返回地址前先判斷該值是否發生了變化就可以預防這種攻擊。Cowan等人提出了函數調用時在緩存區與返回地址之前插入一個canary值,在函數結束返回前判斷這個值是否被修改,如果被修改了就說明出現了棧溢出。随後他們又提出了優化方法PointGuard,對函數指針和longjmp緩存區之後也增加了canary值保護,防止被緩存區溢出操作改寫。ProPolice繼承了Cowan的方法,所不同的是ProPolice重排了局部變量,使得攻擊者很難找到要溢出的緩存區;複制函數參數内的指針到某一個安全區域使得這些指針不會被污染;同時對插樁代碼進行了優化。Hasabnis等人根據canary值原理提出了另一種邊界值檢測方法(LBC)。他們把每個對象的前後都插入一個guardzone,如果程序運行時訪問到任一個guardzone就提示出現了訪問錯誤。他們對guardzone的取值大小和如何插入這些guardzone進行了詳細的研究,但是沒有考慮到當guardzone與源程序代碼片段相同時該怎樣解決;當偏移使得指針從一個對象跳到另一個對象時,該方法也處理不了。為使攻擊者不能猜到canary值,canary取值必須随機化。又因為該方法隻是通過檢測canary值是否改變了來進行緩存區溢出的判斷,不能對隻讀上溢和下溢進行判斷,也不能對堆溢出進行檢測等。
2)參考對象
早期的參考對象技術是在數組越界檢測裡用一個包含指針基地址、指針所指向的空間大小、指針在文件中所處的位置等作為一個多元組來擴展指針的表現形式。在程序中把所有的原指針都以新的指針訪問形式替換,這樣在程序運行時就能根據多元組裡的信息判斷指針訪問是否正确,如CCured、Cyclone等。因為該方法改變了指針的表現形式,導緻處理後代碼與未處理的代碼不兼容。Jones等人提出了一種不改變指針表現形式的方法,它把單個有效的内存塊(變量、數組、結構、聯合等所被分配的内存)作為一個參考對象,用一個全局的對象表收集所有參考對象的基地址、空間大小等信息。在程序運行過程中,當對象創建時,把該對象的相關信息添加到對象表中,當程序運行超出了該對象的作用域或是對象被銷毀時,則從表中删除該對象信息。在訪問該對象時,先查找表,判斷當前訪問是否超出了基地址加大小的範圍,如果超出了,這提示存在緩存區溢出并結束程序。該方法當一個指針訪問出錯時,指向該指針的指針也不能再被檢測,即如果指針p訪問越界,則認為指向p的指針q也是越界的,即使q沒有越界。CRED是對Jones方法的優化,它以ILLEGAL表示一個越界指針,用一個寬松的越界判斷标準解決了上述問題。Dhurjati等人進一步優化了參考對象方法,他們用自動的池分配技術(automaticpoolallocation)把一棵擴展樹分解成多棵樹,極大地減小了指示對象的查找時間,同時從擴展樹上删除了一些多餘的對象,使樹整體上變小了。但是把整數強制轉換為指針等問題沒有很好地被解決。雖然Jones的系列方法解決了程序兼容性問題,但他們把數據類型為數組、結構、聯合等的變量分配的空間單獨作為一個參考,故不能對其中的成員元素進行越界檢測;它隻能對在編譯時就已經明确的操作命令進行檢測,如*p,s.a等這些命令,當對它們取别名用别名來訪問時,就不能被處理。
3)影子内存
影子内存技術是把程序所占的内存所處的狀态映射到一個安全的區域(影子内存)中去,如Dr.Memory就把程序所占内存每一比特的狀态分為不可訪問、未初始化、已經定義的三種狀态。當訪問内存時先查找影子内存中對應比特的狀态,如果是不可訪問的話就說明出現訪問錯誤。典型的映射方法還有直接把地址空間的數值範圍和偏移映射到一個單一的影子地址空間或映射到表結構的影子空間。如TaintTrace用一塊與原地址空間同樣大小的影子空間;Dr.Memory用一個表結構作為影子空間的存儲結構,在訪問時要進行表的查找。為使地址空間的排列更加靈活,一些工具用了多層的映射機制,如Valgrind,在64位的平台上用額外的表來存儲高于32G的地址,LBC用兩級影子内存存放相應的信息。還有其他優化方法如Umbra,憑借non-uniform避免了表查找操作,同時動态地調整了數值範圍與偏移機制;AddressSanitizer用了128-1的映射關系來進行影子狀态的編碼使得内存更加緊湊等。影子内存技術是在位層位對内存進行操作,故映射機制的好壞直接決定了所需影子内存的大小和查找所需要時間的長短。
另寫分析工具
Frama-C提出了一般規格語言ACSL和旨在消除靜态分析和動态分析工具之間區别的ACSL子語言E-ACSL,這兩種語言引入的“注釋”概念是指程序運行中要滿足的一些性質,如檢查指針訪問是否有效、變量有沒有溢出、數組訪問是否越界等。Frama-C在檢測程序時先用“注釋”生成插件,如RTE,把“注釋”插入到原代碼中滿足E-ACSL規範的插件;把這些“注釋”翻譯成C語言,編譯運行翻譯後的代碼,當“注釋”在程序運行過程中不被滿足時,程序終止執行并給出“注釋”所在行列号等信息。如果所有“注釋”在程序運行中都被滿足了,程序不會産生額外的信息,程序所做的功能與未插入“注釋”前是完全一樣的。Frama-C本質上仍然是一種運行時驗證技術,所不同的是它引入了産生“注釋”這一中間過程,把程序的靜态分析與動态分析有機地結合在一起。Frama-C用一個内存監測機制來監測内存的使用情況,在程序執行過程中記錄内存塊的有效性和初始化信息到一個專門的内存區域(該内存區域的存儲結構可以是表、樹等),在内存訪問時執行查詢語句來查找該區域以确定内存的訪問是否正确。雖然ASCS、E-ACSL語言已能處理大部分C語言錯誤,但是它對原程序的性能影響很大,最近Kosmatov等人優化了記錄存儲内容,比較了以哈希表、鍊表、伸展樹、Patricia樹等作為存儲結構對記錄查詢效率的影響,同時還改進了查詢算法,用靜态分析優化了插樁過程,進一步提高了該類語言的可用性。雖然以插件的形式來編寫其他功能代碼使得Frama-C的擴展非常容易,但是從另一方面來說,該系列的語言過于複雜,導緻最後插樁生成的可執行的C文件代碼膨脹過大,程序執行效率降低很多;同時它們對C源文件的處理過程是要先插入“注釋”,然後再把“注釋”翻譯成C類型語言,處理過程複雜,所需時間也長。
基于二進制代碼的分析技術
本文把基于二進制代碼的分析技術分為基于二進制代碼的靜态分析技術和動态分析技術。基于二進制代碼的靜态分析技術是在可執行的二進制代碼上進行靜态分析,找出感興趣的點(如函數調用、緩存區訪問等),在這些點中插入一些語句來檢測程序的運行情況;然後重新生成新的二進制代碼,運行該代碼,如果運行過程中有錯誤發生(如數組越界),則停止程序的執行并報告錯誤。基于二進制代碼的動态分析技術不需要源代碼,在可執行的二進制代碼上修改或添加新的二進制代碼,程序運行過程中調用這些代碼來進行檢測。是否要重新生成新的可執行二進制代碼是基于二進制代碼的靜态分析技術與動态分析技術的不同點。
基于二進制代碼的靜态插樁技術
1)庫函數替換
該技術是在程序鍊接時用重新編寫過的能進行邊界值檢查的函數來替換C、C++标準庫函數中不進行邊界值檢查的函數,這樣當程序運行時,如果邊界檢查未通過,則報告出現緩存區溢出并終止運行。Valgrind是一個開源的直接在二進制上進行插樁的緩存區溢出檢測工具。插入相應的代碼攔截malloc和free函數的運行,然後在一個虛拟的x86處理器上模拟插樁之後代碼的執行,當模拟執行崩潰時,說明緩存區操作出錯,Valgrind會産生相應的錯誤報告。處理相同的程序,Valgrind會比gcc多花25~50倍的時間。Seward等人還擴展了Valgrind的使用,在位精度層面對使用未定義的變量錯誤進行了檢測;在2007年把Valgrind正式擴展為一個動态二進制插樁工具。Chaperon同樣在可執行的二進制代碼上插入代碼來攔截替換malloc、free等函數的執行,通過新的函數來進行堆訪問有效性的驗證、内存洩露、訪問未定義變量錯誤的檢測。Chaperon能對堆緩存區進行有效的檢測,但對棧緩存區的檢測效果不行;當程序因為其他問題而崩潰時,Chaperon也不能進行有效的工作;Chaperon是一個不開源的商業工具,很難對它進行擴展。雖然庫函數替換的方法是在二進制上進行操作,不需要重新編譯源碼,但每調用一次庫函數都要進行邊界值的檢測:對原程序的執行效率影響很大;對靜态連接庫無效;不能預防基于堆或BSS數據段的攻擊等。
2)地址随機化
地址随機化技術是另一種二進制代碼靜态分析方法,它把程序代碼段、數據段等所在内存空間的地址打亂,使攻擊者很難知道某一段代碼、某一個數據在内存空間的地址位置,如随機化變量和函數的順序、随機化系統調用映射和改變庫的入口地址等。一般是用改變傳統的内存分配算法,在程序加載時将内存布局打亂。打亂的原則有随機化代碼與數據的絕對地址和數據地址之間相對的距離。例如地址空間随機化就是把進程空間的地址随機化,使得用絕對地址空間進行攻擊的方法找不到它要攻擊的内存地址,這樣即使被攻擊,程序也隻是崩潰而不會被控制。還有其他随機化方法。例如:PaXASLR能在操作系統的支持下随機化棧、堆、全局空間,但是不能随機化代碼段和靜态數據段的地址;Addressobfuscation擴展了PaxASLR的方法,在編譯器的幫助下能随機化靜态代碼段和數據段的地址,但是導緻了11%的性能損耗;PIE能對全局對象進行處理,該對象基地址的數據段都能被重定位,它也會導緻14%的性能損耗。可見這些方法共有的缺陷是随機化不充分,能被暴力破解,對原程序的性能影響很大。Addressspacelayoutpermutation(ASLP)能對所有的空間地址進行随機化,它用一個二進制重寫工具能随機定位靜态數據段和代碼段,重排列代碼段的函數、數據段的數據對象。又因為是在二進制代碼上進行操作,故不需要源代碼;修改Linux内核使得它能夠随機化棧、堆、内存映射區域。在二進制重寫工具和内核的支持下,ASLP能對32位結構下的29位進行随機化,并且隻損失了1%的性能。但是ASLP不能對棧框架進行随機化,如它不能預防重定位到庫函數的攻擊;如果缺失重定位的信息,ASLP必須重新鍊接或是重新編譯。
基于二進制代碼的動态插樁技術(程序執行流更改)
該技術是在二進制代碼上替換要檢測的函數調用的入口、出口地址,在程序執行過程中,如果遇到函數調用語句,程序執行流直接跳到額外添加的代碼并執行,執行完再跳回原程序執行。Libverify利用_init()函數進行代碼插樁,插樁代碼的功能包括如何确定用戶代碼的位置和大小,如何确定在用戶代碼中函數的開始地址和對每一個函數的操作(複制函數到堆内存,在原函數調用前添加調用函數wrapper_entry和在原函數返回前添加調用函數wrapper_exit),這樣,在每個函數調用前把函數的返回地址通過wrapper_entry函數保存,在函數返回前用wrapper_exit函數來判斷返回地址是否被修改,如果被修改了就說明出現了棧溢出。Gupta等人優化了Libverify方法,他們沒有作函數代碼的複制,隻是在二進制代碼上更改了函數的調用代碼,但是他們隻能對5Byte的指令進行安全的跳轉,當編譯生成的二進制代碼中沒有5Byte的代碼可用來放置跳轉指令時,程序就會出現錯誤。而不同的編譯器對函數調用語句生成的二進制代碼的格式一般是不同的,可見該方法不能通用。雖然程序執行流更改技術隻能對棧緩存區溢出漏洞進行檢測,但是它在修改原來的二進制代碼後,不必重新編譯鍊接生成新的可執行二進制代碼,也就是說它不需要源代碼,這對那些未開源的程序測試是非常有意義的。同時還可以擴展該技術使得在不中斷服務的基礎上對那些提供服務的程序進行檢測。
其他檢測和預防技術
緩存區溢出漏洞自動檢測與修複技術是近幾年才出現的,Arcuri于2008年首次提出了軟件bug自動修複的方法,他用合适的函數(自己設計或是從軟件說明書中自動生成)來進化程序(如用遺傳算法編寫的程序),使之能夠通過一系列單元測試用例,在進化過程中程序得到了修複與完善。雖然該方法存在修複的程序(遺傳程序GP)計算複雜、GP的搜索空間太大、對完整複雜的程序測試不了、複雜的bug也不能被修複等問題,作者還是在一個冒泡排序程序上進行了實驗,說明了其方法是切實可行的。相比Arcuri的方法可以對各種不同的錯誤進行自動修複,SafeStack隻能對棧緩存區溢出漏洞進行修複。以往的自動修複技術需要中斷原程序的執行,修複完之後再重新運行程序,SafeStack是當原程序運行到可能存在緩存區溢出的代碼片段時,跳到SafeStack執行,修複完成後返回原程序執行,因此它不會中斷原程序的執行。它通過内存訪問虛拟化技術把可能存在緩存區溢出的代碼片段移到一個受保護的内存區域中,在該内存中對漏洞進行檢測、補丁生成、補丁測試、補丁運用等操作。SafeStack每一步實現借鑒了其他的技術,如檢測是否存在緩存區溢出的canary方法,補丁生成和評測的First-Aid技術等。可見,緩存區溢出的自動檢測與修複技術可以用協同進化的方法,也可以把現有的檢測技術與修複技術有機地結合在一起。結合的方式一般是先用檢測模塊找出程序中的緩存區溢出漏洞,然後傳遞給修複模塊進行修複,修複完成後再輸入檢測模塊進行檢測,直到不再有漏洞被檢測出來為止。流程如圖4所示。還有很多其他的檢測和預防技術如增加硬件支持技術、增加一個新的堆棧來存放返回地址。在函數返回前判斷該堆棧裡的地址與原堆棧中的返回地址是否一緻來防止返回地址被修改,該類技術對源碼影響小、速度快,但操作系統和編譯器都需要相應的修改;使堆棧不可執行技術,該類技術能有效地預防堆棧緩存區溢出攻擊,同樣需要修改操作系統和編譯器等等。
黑客攪亂緩存
下面讓我們了解一下緩存溢出的原理。衆說周知,c語言不進行數組的邊界檢查,在許多運用c語言實現的應用程序中,都假定緩沖區的大小是足夠的,其容量肯定大于要拷貝的字符串的長度。然而事實并不總是這樣,當程序出錯或者惡意的用戶故意送入一過長的字符串時,便有許多意想不到的事情發生,超過的那部分字符将會覆蓋與數組相鄰的其他變量的空間,使變量出現不可預料的值。如果碰巧,數組與子程序的返回地址鄰近時,便有可能由于超出的一部分字符串覆蓋了子程序的返回地址,而使得子程序執行完畢返回時轉向了另一個無法預料的地址,使程序的執行流程發生了錯誤。甚至,由于應用程序訪問了不在進程地址空間範圍的地址,而使進程發生違例的故障。這種錯誤其實是編程中常犯的。
組成部分
一個利用緩沖區溢出而企圖破壞或非法進入系統的程序通常由如下幾個部分組成:
1.準備一段可以調出一個shell的機器碼形成的字符串,在下面我們将它稱為shellcode。
2.申請一個緩沖區,并将機器碼填入緩沖區的低端。
3.估算機器碼在堆棧中可能的起始位置,并将這個位置寫入緩沖區的高端。這個起始的位置也是我們執行這一程序時需要反複調用的一個參數。
4.将這個緩沖區作為系統一個有緩沖區溢出錯誤程序的入口參數,并執行這個有錯誤的程序。
通過以上的分析和實例,我們可以看到緩存溢出對系統的安全帶來的巨大威脅。在unix系統中,使用一類精心編寫的程序,利用suid程序中存在的這種錯誤可以很輕易地取得系統的超級用戶的權限。當服務程序在端口提供服務時,緩沖區溢出程序可以輕易地将這個服務關閉,使得系統的服務在一定的時間内癱瘓,嚴重的可能使系統立刻宕機,從而變成一種拒絕服務的攻擊。這種錯誤不僅是程序員的錯誤,系統本身在實現的時候出現的這種錯誤更多。如今,緩沖區溢出的錯誤正源源不斷地從unix、windows、路由器、網關以及其他的網絡設備中被發現,并構成了對系統安全威脅數量最大、程度較大的一類。
防範溢出
緩沖區溢出是代碼中固有的漏洞,除了在開發階段要注意編寫正确的代碼之外,對于用戶而言,一般的防範錯誤為
–關閉端口或服務。管理員應該知道自己的系統上安裝了什麼,并且哪些服務正在運行
–安裝軟件廠商的補丁,漏洞一公布,大的廠商就會及時提供補丁
–在防火牆上過濾特殊的流量,無法阻止内部人員的溢出攻擊
–自己檢查關鍵的服務程序,看看是否有可怕的漏洞
-以所需要的最小權限運行軟件



















