發展曆史
五筆字型是一種完全依照漢字的字形、不計讀音,不受方言和地域限制,隻用标準英文鍵盤的25個字母鍵,便能夠以“字詞兼容”的方式,高效率地向電腦輸入漢字的編碼法及其軟件。這一技術,編碼規則簡單明了,重碼少,5區25個鍵位設計規律性強,鍵位負荷與手指功能匹配協調(打起來順手),因而好學易用、效率高,不但在中國裝機最多、應用最廣、一直處于主導地位,而且10多年來在聯合國總部、東南亞各國,其應用也越來越廣。
五筆字型于1983年8月28日鑒定之後,25年間其軟件共有三代版本:
第一代:1986年推出86版五筆,并附有五種筆畫“前四末一”簡易輸入法,史稱86—4.5版;其取碼規範化的一個改進版WB-18030,2001年推出,稱“新86”版或“标準86版”;
第二代:1998年推出98版五筆,增加整字根甫、未、甘、母等,移廣到O鍵;
第三代:2008年元月28日推出,實施了第三代五筆字型的新專利,建立新的字根鍵位體系,處理27533個簡繁漢字,走“徹底規範、親近用戶”的路線,并新創25項功能。
版本對比
第三代五筆字型——新世紀版,是五筆字型發明人王永民教授于1997~1999年用“機助方法”,在《形碼設計三原理》(請參考《計算機學報》2005年第5期870—881頁)數學模型的理論框架下,對86、98版五筆字型的字根體系、鍵盤布局和編碼體系,做定量的優化分析和調整之後,曆時2年,創新設計的一個編碼方案,1999年提出申請,于2003年8月6日獲得中國專利局授權和專利證書。所以,第三代五筆字型,是王永民教授的一項新的發明專利。
三個版本的五筆有很多共同之處,隻有少數字根或字根分布不同,但大部分漢字的編碼都沒有改,編碼規則也保持一緻,隻要記住少數變動的字根,專門挑那些“編碼”不同的字練上幾天,就可以由原來熟悉的五筆版本過渡到新版五筆。王永民教授認為,如果是新學五筆字型的人,最好能“一步到位”學習第三代(新世紀版)。因為從長遠看,王碼公司将要用新世紀版“統一全國”的“形碼”輸入法,包括納入中小學教育之中。
第三代五筆字型從理論和實踐兩個方面,都取得了質的突破,實現了對第一代和第二代的再創新。第三代的各項技術指标,包括字根的增減或移位、鍵位負荷的均衡設計、簡繁漢字的簡碼設計、漢字“大小寫”的定義和應用、容錯碼設計以及《助記歌》等等,與前兩代比,都有質的進步。從實用性評價,其重碼實用頻度降低,取碼規範化,打起順手;規律性、易學性等方面也都有顯著的進步。所以,發明人王永民教授說,第三代五筆字型(新世紀版)将是他30年來研究五筆字型的一個“終極版”,“第三代是個大方向”!王碼集團将以這個版本為核心,統一全國的“形碼”輸入法。
新版特點
1983年發行第一版的五筆字型,到1986年推出86版定型版,1998年通過鑒定并推出的98版五筆字型,在編碼的規範性上做了一定的改進,但在适應性、字根易記性等方面,仍有欠餘。新世紀版對86版和98版做了如下改進:
1、規範性
86版在某些字中的末筆識别碼的取法上遷就了習慣寫法,如:我、找、龍、成……
這些字由于有一大部分有倒插筆的習慣,所以在86版中,人為地規定末筆為“丿”。而在國家筆順規範中,這些字的末筆為“丶”,因此,在新世紀版編碼時,統一将這些字規定為依照國家标準,末筆均定義為“丶”。
98版在編碼取碼上進行了規範性的改進,象“我、找”等字,用戶書寫習慣有的是以“丿”為末筆,有的是以“丶”為末筆,在98版中,都按照國家筆順規範,定義這些字的末筆為“丶”,在新世紀版編碼體系中,同樣也沿襲了這些标準,末筆均定義為“丶”。
2、字根精減
為确保編碼方案最優,為更加方便用戶記憶字根,新世紀版字根有所減少,比86版和98版都少了許多字根。
3、鍵位變動
以理論與實踐為基礎,為确保編碼方案最優,對86版的7個字根的鍵位做了變動,放置在新世紀版的字根圖中。如:字根“乃”,在86版中是在“E”鍵上,但由于其規範筆順為“乙、丿”,所以,新世紀中将該字根安排在了“乙”區的“B”鍵上。
對98版的4個字根的鍵位做了變動,重新放置在新世紀版的字根圖中。如:字根“牜”,在98版中是在“C”鍵上,考慮該字根以“丿”起筆,所以,新世紀中将該字根放在了“丿”區的“T”鍵上。
4、編碼兼容
新世紀版有着科學、完備的的編碼體系,與86版、98版均有不同之處,但用戶不用擔心,新世紀版對這兩個版本均做了兼容處理。
基礎知識
漢字的5種筆畫
字根是由筆畫寫成。筆畫、字根(部件)、整字,是漢字結構的三個層次。
1984年王永民教授給筆畫定義為:書寫漢字時,一次寫成的一個連續不斷的線段。按照書寫方向劃分筆畫的類型,如下圖所示,則隻有5種——橫、豎、撇、捺、折。前4種是單方向的筆畫,“折”則代表一切帶轉折、拐彎的筆畫。為了便于記憶和排序,我們分别用1、2、3、4、5命名5種筆畫的代号。
以下例子可作為這張表的補充說明:
(1)“提筆”等于“橫”:王現
(2)“點”等于“捺”:木村
(3)“豎左鈎”等于“豎”:禾
(4)所有帶轉折的筆畫都算作“折”。
為便于書面表示,以後所有的“折”筆,不管怎麼“折”,怎麼“彎”,怎麼“拐”,一律都有“乙”來表示,其筆畫代号都是5。
王永民對筆畫的以上分類法及代号,現在已經被正式寫入了代号為GB/T18031-2000的國家标準中。
給筆畫分類,并命名以數字代号,是學習王碼輸入法時最重要的基礎知識。在實踐中,許多人之所以編碼出現錯誤,或對鍵盤上碼元排列的規律性“視而不見”,其根本原因,常是因為沒有掌握好五種單筆畫的分類及其數字代号。
漢字的3種字型
習慣上,我們把構成漢字的基本筆畫結構,稱作“字根”或“部件”。而當“字根”或“部件”用于編碼的時候,又可以把它們叫做“碼元”,意思是編碼的“元素”。
漢字是一種平面文字,同樣幾個字根,同樣的先後順序,擺放的位置不同,就是不同的字。如:
叭——隻 吧——邑
呐——呙 豈——屺
可見,字根相互間的位置關系,也是漢字圖形的一個特征,在漢字編碼中,用數字代表這個特征,就成為很有用的、用以分區“重碼”的“識别”信息。
根據構成漢字的各個字根之間的位置關系,我們可以把成千上萬的方塊漢字,分為三種字型:
左右型:字根左右排列。
上下型:字根上下排列。
雜合型:字根互相周圍或交叉套叠。
根據各種字型擁有漢字的多少,順序将字型命以數字代号,如下表所示。
我們便約定:
1型字,即指“左右型”漢字,其代号為1;
2型字,即指“上下型”漢字,其代号為2;
3型字,即指“雜合型”漢字,其代号為3。
将來,我們給漢字編碼時,字型及其代号将非常有用。
這裡應當說明,在王碼中,僅僅對于那些由2個或3個字根組成的字,我們才關心它的“字型”。如果一個字由4個或4個以上的字根組成,例如:編碼中,我們就不再計較是什麼“型”了。
鍵位分布
認識五筆字型鍵盤
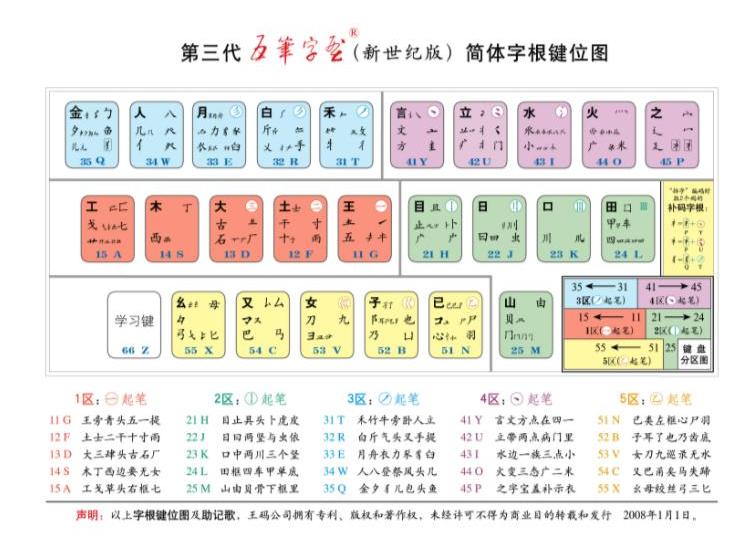
五筆字型采用标準英文鍵盤的26個字母鍵輸入漢字。每個漢字,每條詞彙最多打4下鍵。漢字是由字根構成的。我們将構成漢字的字根,優選歸納為125種,也稱作“碼元”,分配在除Z鍵以外的25個英文字母鍵上,形成了五筆字型的“字根鍵盤”。新世紀版五筆字型字根鍵位圖:
新世紀版字根助記歌
為保持技術的連續性,第三代五筆字型(新世紀版)的25個“鍵名”沒有變動。新設計的字根體系更加符合分區劃位規律,更加科學易記而實用,按規範筆順寫漢字的人,取碼輸入将得心應手。新世紀版的《字根助記歌》如下:
1區橫起筆
11G,王旁青頭五一提
12F,土士二幹十寸雨
13D,大三肆頭古石廠
14S,木丁西邊要無女
15A,工戈草頭右框七
2區豎起筆
21H,目止具頭蔔虎皮
22J,日曰兩豎與蟲依
23K,口中兩川三個豎
24L,田框四車甲單底
25M,山由貝骨下框裡
3區撇起筆
31T,禾竹牛旁卧人立
32R,白斤氣頭叉手提
33E,月舟衣力豕豸臼
34W,人八登祭風頭幾
35Q,金夕犭兒包頭魚
4區點起筆
41Y,言文方點在四一
42U,立帶兩點病門裡
43I,水邊一族三點小
44O,火變三态廣二米
45P,之字寶蓋補示衣
5區折起筆
51N,已類左框心屍羽
52B,子耳了也乃齒底
53V,女刀九巡錄無水
54C,又巴甬矣馬失蹄
55X,幺母絞絲弓三匕
鍵盤上字根的記憶規律
在五筆字型鍵盤上,多數字根(碼元)的安排都是有規律的。字根鍵盤分為5個區,區号為1~5;每一個區,各有5個鍵位,位号也是1~5,從鍵盤中部向外端排列;區号與位号組合,共形成5×5=25個代碼,即區位碼:11…15,21…51…55。其規律性如下:
1、字根所在的"區号"與"首筆代碼"一緻
①橫起筆的字根,在第1區——“王土大木工”的首筆代号為1;
②豎起筆的字根,在第2區——“目日口田山”的首筆代号為2;
③撇起筆的字根,在第3區——“禾白月人金”的首筆代号為3;
④點起筆的字根,在第4區——“言立水火之”的首筆代号為4;
⑤折起筆的字根,在第5區——“已子女又幺”的首筆代号為5。
2、位号基本上與碼元的次筆代碼一緻
3、單筆畫的“個數”,與所在的“位号”一緻
一、丨、丿、丶、乙都在相應區的第1位;
二、刂、丿丿、丶丶、巜都在各區的第2位;
三、彡、氵、巛都在各區的第3位;
四、灬在相應區的第4位。
4、從字根上“直讀”區位号
依照以上3條規律,根據字根的“前兩個筆畫”,可立即“直讀”出“字根”的區位号(即:前2個筆畫的代号連在一起念,就是區位号!):
例:參——厶大彡
●厶:首筆為折(5),次筆為點(4),故“厶”在第5區第4位(54、C)
●大:首筆為橫(1),次筆為撇(3),故“大”在第1區第3位(13、D)
●彡:首筆為撇(3),次筆為撇(3),故“彡”在第3區第3位(33、E)
單字輸入
編碼流程圖
五筆字型将成千上萬個漢字首先分成兩大類:鍵面上有的“鍵面字”和鍵面上沒有的“鍵外字”。兩類漢字的取碼法按以下流程圖分别取碼。
鍵面字的編碼輸入
五筆字型字根鍵盤上,本身是漢字的字根,叫“鍵面字”。“鍵面字”分為三類,其輸入法分别是:
1、鍵名字的輸入
每一個鍵位上,最左上角的那個黑體字的碼元,叫鍵名字,它是“一鍵之名”。以G鍵為例,其左上角的字根“王”便是“鍵名字”或“鍵名”。
“鍵名字”的輸入法是:把所在的鍵連打4下。例如:
1區1位鍵名:王11,11,11,11,(GGGG)
3區2位鍵名:白32,32,32,32,(RRRR)
4區5位鍵名:之45,45,45,45,(PPPP)
5區3位鍵名:女53,53,53,53,(VVVV)
在王碼五筆字型中,鍵名碼元有25個。
1區:王土大木工(對應鍵位:GFDSA)
2區:目日口田山(對應鍵位:HJKLM)
3區:禾白月人金(對應鍵位:TREWQ)
4區:言立水火之(對應鍵位:YUIOP)
5區:已子女又纟(對應鍵位:NBVCX)
2、成字字根的輸入
鍵面上除鍵名外,凡本身是漢字的碼元,叫“成字字根”或“成字碼元”。其輸入法是:先打一下它所在的鍵(這一下俗稱“報戶口”),再打第一個、第二個,以及它的最末一個單筆畫,最多4下,不足4下,補一個空格鍵。例如:
當輸入十、七、九、二、幾、兒、乃、刀……這一類隻有2個筆畫的字根時,“報戶口”之後就隻能有兩個筆畫了,不足4個碼,筆畫打完,要再補打一下“空格鍵”表示結束。
3、補碼碼元及其輸入
在字根表中,用方圓框“框住”的4個字根,是“補碼碼元”,它們作為字根參與編碼時,像姓氏中的複姓諸葛、司馬一樣,要編2個碼:“主碼(即碼元所在鍵位)+補碼(規定取該碼元最後的筆畫結構)”。如下表所示:
注:表中帶圓圈的筆畫丶、氵等,是“補碼”的筆畫表示形式,作為一個符号,用以提示編碼。
這4個補碼碼元中的“犭、礻、衤”等三個字根,本身也是漢字,這三個漢字的編碼規則是,要先“報戶口”(主碼+補碼)(已占用2個碼)、再打該字的第1筆和最後1筆,共取4碼。即:
注:鍵位上隻有有的成字的字根可以打出來,而本身并不是漢字字根不能打出來。
“鍵外字”的拆分法
凡是“字根總表”上沒有的漢字,都是“鍵外字”。它們都是由幾個碼元(字根)組合而成的,我們也把這類字稱為“多元字”。
對于“多元字”,隻有一個字——拆分。科學、實用又沒有“二義性”的“拆”法,共有以下5項規則:
1、書寫順序
“合體字”拆成“字根”,一般情況下,要按照正确書寫順序進行。例如:
新:立木斤(順序正确)
立斤木(順序錯誤)
2、取大優先
要“拆”出“筆畫盡可能多”的“字根”。要以“再添一個筆畫,便不能構成為筆畫更多的字根”為限度。例如:
估:亻古(正确)
亻十口(錯誤,因為“口”可添到前面的“十”上,“湊”成更多筆畫的字根“古”)
注:“取大優先”,俗稱“盡量往前湊”。因為“向前湊”總是有限度的,要湊成字根表中筆畫更多(更大)的一個!否則,便沒有“章法”了,勢必有許多種“拆法”甚至都要拆成單筆畫!在漢字拆分中,這是一個最常用到的、保證拆分唯一性的基本原則。
3、兼顧直觀
在編碼時,為了使碼元特征明顯易辨,有時就要暫時犧牲“書寫順序”和“取大優先”的原則,形成個别例外的情況。
例:“國”字
按“書寫順序”,其碼元應是:“冂王丶一”,但這樣編碼,不但有悖于該字的字源,也不能使碼元“囗”直觀易辨。我們隻好違背“書寫順序”,按“囗王丶”的順序編碼。
4、能連不交
請看以下取碼實例:
天:一大(正确,“一”與“大”是相連接的關系,比較直觀)
二人(錯誤,“二”與“人”交叉在一起了)
生:丿?(正确,“丿”與“?”是相連的,直觀可取)
土(錯誤,“丿”與“?”是相連的,直觀可取)
一般來說,“連”比“交”更為“直觀”,更能顯現碼元的筆畫結構特征,更易于辨認。
5、能散不連
有時候,一個漢字的幾個碼元,都不是單筆畫,這些碼元之間的關系,常常在“散”和“連”之間模棱兩可。如:
矢:?大,兩個碼元按“連”處理,“矢”便是雜合型(3型)字;兩個碼元如果按“散”處理,“矢”便是上下型(2型)字。
午:?、十(兩個字根,可視為散,也可當作連)
都是既可“連”,又可“散”的關系。
當遇到這種既能“散”,又能“連”的情況時,我們規定:隻要不是單筆畫,一律按“能散不連”判别,即優先确定為“散”的關系。
四元及多元字的取碼
1、“四元字”的編碼規則
鍵外字中的“四元字”,是指剛好由四個字根構成的字。其拆分之後的取碼方法是“依照書寫順序輸入字根”。例如:
照:日刀口灬
22,53,23,44
J,V,K,O
重:丿一日土
31,11,22,12
T,G,J,F
2、“多元字”的取碼規則——“前三末一”(一二三末)
鍵外字中的“多元字”,是指由4個以上的字根構成的字。這種字,不管實際上能“拆”成幾個字根,我們隻需“按書寫順序,取拆分結果的第一二三及最末一個字根”便可,俗稱“一二三末”,共輸入四個碼。例如:
暨:彐厶匚兒日一
53,54,15,11
V,C,A,G
攀:木乂乂木大手
14,32,32,32
S,R,R,R
末筆字型識别碼
漢字編碼輸入法的設計,要盡量減少重碼,以提高輸入的唯一性。但從以下兩種情形我們看到,僅僅輸入字根,很容易産生重碼:
1、因構字的字根相同,字型不同引起重碼:
叭:口八(23,34,KW)
隻:口八(23,34,KW)
這個例子說明,編碼中丢失了字型信息,才産生了重碼。
2、因幾個字根同一鍵位引起重碼:
沐:氵木(43,14,IS)
汀:氵丁(43,14,IS)
灑:氵西(43,14,IS)
這個例子說明,編碼沒有将“木、丁、西”加以區分,才産生了重碼。
由以上兩類例子可知,當遇到2-3個字根構成的漢字時,為了避免編碼相同(重碼),既有必要提取“字型信息”,又有必要從字根上“提取筆畫特征信息”用于編碼。複合這兩種信息的一個附加碼,就是“末筆字型識别碼”簡稱“識别碼”,“識别碼”隻追加在由2-3個字根構成的漢字編碼中(見下節)。
“識别碼”是由“末筆”代号加“字型”代号構成的一個“複合附加碼”。1、2、3型漢字的識别碼共有15個(各有3種形式),其構成如下:
例:紅:末筆1,字型1,識别碼為11(即“一”);
華:末筆2,字型2,識别碼為22(即“刂”);
團:末筆3,字型3,識别碼為33(即“彡”)。
二元及三元字的取碼
“鍵外字”中,隻有2個字根的字,叫“二元字”;隻有3個字根的字,叫“三元字”。輸入時,鍵外字毫無例外地都要“拆”。
“二元字”或“三元字”的輸入法是:
先“拆”成字根,輸入字根後,再追加一個“末筆字型識别碼”(簡稱“識别碼”)。有了識别碼可以大量減少重碼。
“識别碼”的簡易直觀表示法——用帶圓圈的筆畫表示“識别碼”:
1、左右型(1型)字的“識别碼”
對于1型(左右型)字,字根輸入之後,補打“1個末筆畫”,就等同于添加了“識别碼”,用“一丨丿丶乙”表示。例如:
紅:纟工一(字根打完,補打1個末筆畫“一”,相當于11:G)
55,15,11
X,A,G
2、上下型(2型)字的“識别碼
對于2型(上下型)字,碼元輸入之後,補打“2個末筆畫”的字根,就等同于添加了“識别碼”,用“二刂丿丿丶丶巜”表示之。例如:
字:宀子二(字根打完,補打2個末筆畫“二”相當于12:F)
45,52,12
P,B,F
複:?,日,夂(字根打完,補打2個末筆畫“丶丶”,相當于42:U)
31,22,31,42
T,J,T,U
花:艹亻匕巜(字根打完,補打2個末筆畫“巜”,相當于52:B)
15,34,55,52
A,W,X,B
3、雜合型(3型)字的“識别碼”
對于3型(雜合型)字,碼元輸完之後,補打“3個末筆畫”的字根,就等同于添加了“識别碼”,用“三川彡氵巛”表示之。例如:
同:冂一口三(字根打完,補打3個末筆畫“三”,相當于13:D)
25,11,23,13
M,G,K,D
遠:二兒辶巛(字根打完,補打3個末筆畫“巛”,相當于53:V)
12,35,45,53
F,Q,P,V
注1:凡是“包圍型”的字,如全包圍字“國、團”等,半包圍字“這、慶”等,均以被包圍的那個部分的“末筆”作為整個字的“末筆”來構成“識别碼”,如“遠”字,要以被包圍的“兒”的末筆來構成“識别碼”(53:V)。
注2:識别碼一共有3種表示法,其編碼的效果完全相同,都是同一個碼。可以按照下面的方法打“識别碼”,例如:
末筆橫的1型字:打11鍵,就是G鍵,就是“一”(一個橫)鍵。
末筆撇的3型字:打33鍵,就是E鍵,就是“彡”(三個撇)鍵。
其所以如此,道理很簡單:1區1位(G)上有1個橫“一”,3區3位(E)上有3個撇“彡”……
簡碼和容錯碼輸入
1、簡碼輸入
一些常用的字,除按它的“全碼”可輸入外,為減少打鍵次數,隻輸入其全碼的最前邊的1個、2個或3個碼,再加打空格鍵,也可以輸入,這就是一、二、三級簡碼。簡碼可以提高輸入效率。
(1)一級簡碼(又稱“高頻字”)
将各鍵打一下,再打一下空格鍵,即可打出25個最常用的漢字(每鍵一個):
一地在要工 上是中國同 和的有人我 主産不為這 民了發以經
如:一:11(G) 的:32(R) 和:31(T)
具體如下表:
(2)二級簡碼(隻輸入“全碼”的前2個碼)
化:亻匕(34,55,WX)
李:木子(14,52,SB)
(3)三級簡碼(隻輸入“全碼”的前3個碼)
想:木目心(14,21,51,SHN)
巍:山禾女(25,31,53,MTV)
2、容錯碼
“容錯碼”的涵義是:“容易”編錯,但“容許”按錯碼輸入。例如:
面:丆冂三DMJD(正确,按筆順取大優先)丆囗二DMJF(拆分容錯)
萬能鍵Z
輸入漢字時,如果一時不知道某些字的編碼,便可以用“萬能鍵Z”來代替“不知道的那個碼”。Z鍵的用途主要可分以下三種情況:
1.當不知道某個字的拆分時,用Z代替不知道的字根,例:
鍵:钅,Z,Z,廴
2.當不知道字根在哪個鍵位上時,用Z代替,例:
論:讠,人,Z,Z
3.當不知道字的“識别碼”時,可用Z代替,例:
花:艹,亻,匕,Z
萬能鍵Z也叫學習鍵。一旦使用Z鍵,提示行中便會有比較多的字顯示出來,其中會有你要的那個字,而且,字的後邊還有正确碼的提示。
詞彙輸入
在字母鍵上,打4個鍵,不用換檔,既能打單字,又能打詞彙,字、詞之間沒有界限,這是發明人1983年的一項重大創造——字詞兼容。
在輸入詞彙時,不管多長的詞彙,一律隻打4下鍵,單字和詞彙可以混合輸入,字詞之間不用任何換檔或其它附加操作。詞彙輸入法為:
二字詞
取每個字“全碼”的前兩個碼組成,共4碼。
例如:
生産:丿 ? 立 丿
31 11 42 31(TGUT)
建設:彐 二 讠 幾
53 12 41 34(VGYW)
三字詞
前兩個字,各取第一個碼,最後一字取前兩個碼,共4碼。
例如:
電視機:日礻木幾
22,45,14,25(JPSW)
四字或四字以上的詞
對于4個字或超過4個字的詞,取第一、二、三及最後一個漢字的第一碼,共4碼。
例如:
中華人民共和國:口亻人囗
23,34,34,24,(KWWL)