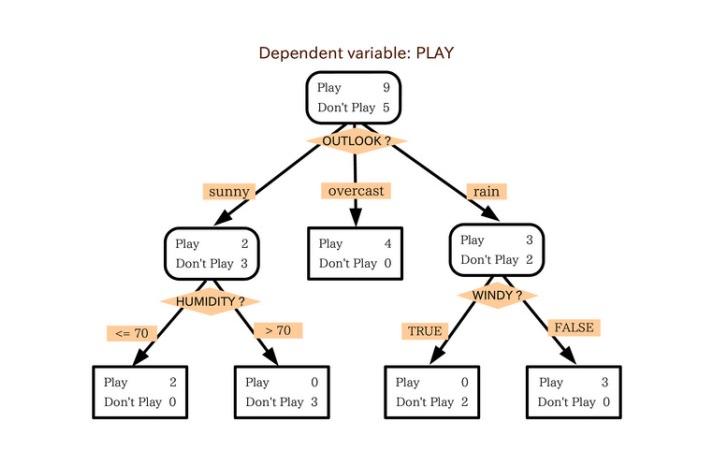
組成
□——決策點,是對幾種可能方案的選擇,即最後選擇的最佳方案。如果決策屬于多級決策,則決策樹的中間可以有多個決策點,以決策樹根部的決策點為最終決策方案。
○——狀态節點,代表備選方案的經濟效果(期望值),通過各狀态節點的經濟效果的對比,按照一定的決策标準就可以選出最佳方案。由狀态節點引出的分支稱為概率枝,概率枝的數目表示可能出現的自然狀态數目每個分枝上要注明該狀态出現的概率。
△——結果節點,将每個方案在各種自然狀态下取得的損益值标注于結果節點的右端。
畫法
機器學習中,決策樹是一個預測模型;他代表的是對象屬性與對象值之間的一種映射關系。樹中每個節點表示某個對象,而每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應從根節點到該葉節點所經曆的路徑所表示的對象的值。決策樹僅有單一輸出,若欲有複數輸出,可以建立獨立的決策樹以處理不同輸出。數據挖掘中決策樹是一種經常要用到的技術,可以用于分析數據,同樣也可以用來作預測。
從數據産生決策樹的機器學習技術叫做決策樹學習, 通俗說就是決策樹。
一個決策樹包含三種類型的節點:
決策節點:通常用矩形框來表示
機會節點:通常用圓圈來表示
終結點:通常用三角形來表示
決策樹學習也是資料探勘中一個普通的方法。在這裡,每個決策樹都表述了一種樹型結構,它由它的分支來對該類型的對象依靠屬性進行分類。每個決策樹可以依靠對源數據庫的分割進行數據測試。這個過程可以遞歸式的對樹進行修剪。 當不能再進行分割或一個單獨的類可以被應用于某一分支時,遞歸過程就完成了。另外,随機森林分類器将許多決策樹結合起來以提升分類的正确率。
決策樹同時也可以依靠計算條件概率來構造。
決策樹如果依靠數學的計算方法可以取得更加理想的效果。 數據庫已如下所示:
(x, y) = (x1, x2, x3…, xk, y)
相關的變量 Y 表示我們嘗試去理解,分類或者更一般化的結果。 其他的變量x1, x2, x3 等則是幫助我們達到目的的變量。
決策樹的剪枝
剪枝是決策樹停止分支的方法之一,剪枝有分預先剪枝和後剪枝兩種。預先剪枝是在樹的生長過程中設定一個指标,當達到該指标時就停止生長,這樣做容易産生“視界局限”,就是一旦停止分支,使得節點N成為葉節點,就斷絕了其後繼節點進行“好”的分支操作的任何可能性。不嚴格的說這些已停止的分支會誤導學習算法,導緻産生的樹不純度降差最大的地方過分靠近根節點。後剪枝中樹首先要充分生長,直到葉節點都有最小的不純度值為止,因而可以克服“視界局限”。然後對所有相鄰的成對葉節點考慮是否消去它們,如果消去能引起令人滿意的不純度增長,那麼執行消去,并令它們的公共父節點成為新的葉節點。這種“合并”葉節點的做法和節點分支的過程恰好相反,經過剪枝後葉節點常常會分布在很寬的層次上,樹也變得非平衡。後剪枝技術的優點是克服了“視界局限”效應,而且無需保留部分樣本用于交叉驗證,所以可以充分利用全部訓練集的信息。但後剪枝的計算量代價比預剪枝方法大得多,特别是在大樣本集中,不過對于小樣本的情況,後剪枝方法還是優于預剪枝方法的。
優點
決策樹易于理解和實現,人們在在學習過程中不需要使用者了解很多的背景知識,這同時是它的能夠直接體現數據的特點,隻要通過解釋後都有能力去理解決策樹所表達的意義。
對于決策樹,數據的準備往往是簡單或者是不必要的,而且能夠同時處理數據型和常規型屬性,在相對短的時間内能夠對大型數據源做出可行且效果良好的結果。
易于通過靜态測試來對模型進行評測,可以測定模型可信度;如果給定一個觀察的模型,那麼根據所産生的決策樹很容易推出相應的邏輯表達式。
缺點
對連續性的字段比較難預測。對有時間順序的數據,需要很多預處理的工作。當類别太多時,錯誤可能就會增加的比較快。一般的算法分類的時候,隻是根據一個字段來分類。算法
C4.5
C4.5算法繼承了ID3算法的優點,并在以下幾方面對ID3算法進行了改進:
1) 用信息增益率來選擇屬性,克服了用信息增益選擇屬性時偏向選擇取值多的屬性的不足;
2) 在樹構造過程中進行剪枝;
3) 能夠完成對連續屬性的離散化處理;
4) 能夠對不完整數據進行處理。
C4.5算法有如下優點:産生的分類規則易于理解,準确率較高。其缺點是:在構造樹的過程中,需要對數據集進行多次的順序掃描和排序,因而導緻算法的低效。此外,C4.5隻适合于能夠駐留于内存的數據集,當訓練集大得無法在内存容納時程序無法運行。
具體算法步驟如下;
1創建節點N
2如果訓練集為空,在返回節點N标記為Failure
3如果訓練集中的所有記錄都屬于同一個類别,則以該類别标記節點N
4如果候選屬性為空,則返回N作為葉節點,标記為訓練集中最普通的類;
5for each 候選屬性 attribute_list
6if 候選屬性是連續的then
7對該屬性進行離散化
8選擇候選屬性attribute_list中具有最高信息增益率的屬性D
9标記節點N為屬性D
10for each 屬性D的一緻值d
11由節點N長出一個條件為D=d的分支
12設s是訓練集中D=d的訓練樣本的集合
13if s為空
14加上一個樹葉,标記為訓練集中最普通的類
15else加上一個有C4.5(R - {D},C,s)返回的點
CART
背景:
分類與回歸樹(CART——Classification And Regression Tree)) 是一種非常有趣并且十分有效的非參數分類和回歸方法。它通過構建二叉樹達到預測目的。
分類與回歸樹CART 模型最早由Breiman 等人提出,已經在統計領域和數據挖掘技術中普遍使用。它采用與傳統統計學完全不同的方式構建預測準則,它是以二叉樹的形式給出,易于理解、使用和解釋。由CART 模型構建的預測樹在很多情況下比常用的統計方法構建的代數學預測準則更加準确,且數據越複雜、變量越多,算法的優越性就越顯著。模型的關鍵是預測準則的構建,準确的。
定義:
分類和回歸首先利用已知的多變量數據構建預測準則, 進而根據其它變量值對一個變量進行預測。在分類中, 人們往往先對某一客體進行各種測量, 然後利用一定的分類準則确定該客體歸屬那一類。例如, 給定某一化石的鑒定特征, 預測該化石屬那一科、那一屬, 甚至那一種。另外一個例子是, 已知某一地區的地質和物化探信息, 預測該區是否有礦。回歸則與分類不同, 它被用來預測客體的某一數值, 而不是客體的歸類。例如, 給定某一地區的礦産資源特征, 預測該區的資源量。
實例
為了适應市場的需要,某地準備擴大電視機生産。市場預測表明:産品銷路好的概率為0.7;銷路差的概率為0.3。備選方案有三個:第一個方案是建設大工廠,需要投資600萬元,可使用10年;如銷路好,每年可赢利200萬元;如銷路不好,每年會虧損40萬元。第二個方案是建設小工廠,需投資280萬元;如銷路好,每年可赢利80萬元;如銷路不好,每年也會赢利60萬元。第三個方案也是先建設小工廠,但是如銷路好,3年後擴建,擴建需投資400萬元,可使用7年,擴建後每年會赢利190萬元。
各點期望:
點②:0.7×200×10+0.3×(-40)×10-600(投資)=680(萬元)
點⑤:1.0×190×7-400=930(萬元)
點⑥:1.0×80×7=560(萬元)
比較決策點4的情況可以看到,由于點⑤(930萬元)與點⑥(560萬元)相比,點⑤的期望利潤值較大,因此應采用擴建的方案,而舍棄不擴建的方案。把點⑤的930萬元移到點4來,可計算出點③的期望利潤值。
點③:0.7×80×3+0.7×930+0.3×60×(3+7)-280 = 719(萬元)
最後比較決策點1的情況。由于點③(719萬元)與點②(680萬元)相比,點③的期望利潤值較大,因此取點③而舍點②。這樣,相比之下,建設大工廠的方案不是最優方案,合理的策略應采用前3年建小工廠,如銷路好,後7年進行擴建的方案。









![連續[數學名詞]](https://img.shiliuwang.cn/uploadfile/images/5b1bba4f2bb4ca6af08fe87c80b05c35.jpg)