簡介
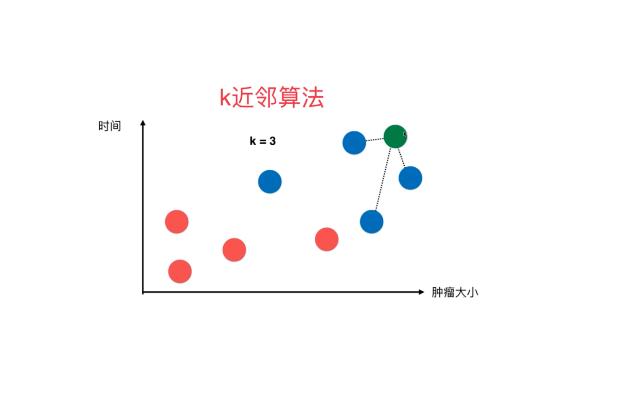
KNN(K- Nearest Neighbor)法即K最鄰近法,最初由 Cover和Hart于1968年提出,是一個理論上比較成熟的方法,也是最簡單的機器學習算法之一。
該方法的思路非常簡單直觀:如果一個樣本在特征空間中的K個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類别,則該樣本也屬于這個類别。該方法在定類決策上隻依據最鄰近的一個或者幾個樣本的類别來決定待分樣本所屬的類。
該方法的不足之處是計算量較大,因為對每一個待分類的文本都要計算它到全體已知樣本的距離,才能求得它的K個最鄰近點。目前常用的解決方法是事先對已知樣本點進行剪輯,事先去除對分類作用不大的樣本。另外還有一種 Reverse KNN法,它能降低KNN算法的計算複雜度,提高分類的效率。
KNN算法比較适用于樣本容量比較大的類域的自動分類,而那些樣本容量較小的類域采用這種算法比較容易産生誤分。
核心思想
KNN算法的核心思想是,如果一個樣本在特征空間中的K個最相鄰的樣本中的大多數屬于某一個類别,則該樣本也屬于這個類别,并具有這個類别上樣本的特性。
該方法在确定分類決策上隻依據最鄰近的一個或者幾個樣本的類别來決定待分樣本所屬的類别。KNN方法在類别決策時,隻與極少量的相鄰樣本有關。由于KNN方法主要靠周圍有限的鄰近的樣本,而不是靠判别類域的方法來确定所屬類别的,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為适合。
算法流程
總體來說,KNN分類算法包括以下4個步驟:
①準備數據,對數據進行預處理 。②計算測試樣本點(也就是待分類點)到其他每個樣本點的距離。③對每個距離進行排序,然後選擇出距離最小的K個點 。④對K個點所屬的類别進行比較,根據少數服從多數的原則,将測試樣本點歸入在K個點中占比最高的那一類。
優點
KNN方法思路簡單,易于理解,易于實現,無需估計參數 。
缺點
該算法在分類時有個主要的不足是,當樣本不平衡時,如一個類的樣本容量很大,而其他類樣本容量很小時,有可能導緻當輸入一個新樣本時,該樣本的K個鄰居中大容量類的樣本占多數。該方法的另一個不足之處是計算量較大,因為對每一個待分類的文本都要計算它到全體已知樣本的距離,才能求得它的K個最近鄰點 。
改進策略
目前對KNN算法改進的方向主要可以分為4類:
一是尋求更接近于實際的距離函數以取代标準的歐氏距離,典型的工作包括 WAKNN、VDM;
二是搜索更加合理的K值以取代指定大小的K值典型的工作包括SNNB、 DKNAW ;
三是運用更加精确的概率估測方法去取代簡單的投票機制,典型的工作包括 KNNDW、LWNB、 ICLNB;
四是建立高效的索引,以提高KNN算法的運行效率,代表性的研究工作包括 KDTree、 NBTree。還有部分研究工作綜合了以上的多種改進方法。