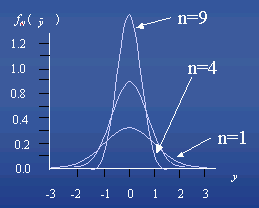
定义
在数理统计中,统计估计与推断需要我们进行抽样来估计,而样本是统计估计和推断的依据,所以在处理具体理论与应用问题时,我们很少直接利用样本,而是利用它们经过适当处理导出来的量,这个量也就是统计量,统计量的分布也就是抽样分布。
以样本平均数为例,它是总体平均数的一个估计量,如果按照相同的样本容量,相同的抽样方式,反复地抽取样本,每次可以计算一个平均数,所有可能样本的平均数所形成的分布,就是样本平均数的抽样分布。
类型n
单一样本统计量
当我们要对某一总体的参数进行估计时,就要研究来自该总体的所有可能的样本统计量的分布问题,比如样本均值的分布、样本比例的分布,从而概括有关统计量抽样分布的一般规律。n
样本均值
1.形成
样本均值的抽样分布即所有样本均值的可能取值形成的概率分布。例如,某高校大一年级参加英语四级考试的人数为6000人,为了研究这6000人的平均考分,欲从中随机抽取500人组成样本进行观察。若逐一抽取全部可能样本,并计算出每个样本的平均考分,将会得出很多不完全相同的样本均值,全部可能的样本均值有一个相应的概率分布,即为样本均值的抽样分布。n
2.特征
从抽样分布的角度看,我们所关心的分布的特征主要是数学期望和方差。这两个特征一方面与总体分布的均值和方差有关,另一方面也与抽样的方法是重复抽样还是不重复抽样有关。
3.形式
样本均值抽样分布的形式与原有总体的分布和样本容量n的大小有关。n如果原有总体是正态分布,那么,无论样本容量的大小,样本均值的抽样分布都服从正态分布。n如果原有总体的分布是非正态分布,就要看样本容量的大小。随着样本容量n的增大(通常要求n≥30),不论原来的总体是否服从正态分布,样本均值的抽样分布都将趋于正态分布,即统计上著名的中心极限定理。n虽然总体成绩的分布形态未知,但σ已知,且n=150为大样本,依据中心极限定理可知:样本均值的抽样分布近似服从正态分布。n
样本比例
样本比例即指样本中具有某种特征的单位所占的比例。样本比例的抽样分布就是所有样本比例的可能取值形成的概率分布。例如,某高校大一年级学生参加英语四级考试的人数有6000人,为了估计这6000人中男生所占的比例,从中抽取500人组成样本进行观察,若逐一抽取全部可能样本,并计算出每个样本的男生比例,则全部可能的样本比例的概率分布,即为样本比例的抽样分布。可见,样本比例也是一个随机变量。n
1.特征n
在大样本情况下,样本比例的抽样分布特征可概括如下:n
无论是重复抽样还是不重复抽样,样本比例p的数学期望总是等于总体比例Pn
2.形式n
样本比例的分布属于二项分布问题,当样本容量n足够大时,即当nP与n(1-P)都不小于5时,样本比例的抽样分布近似为正态分布。n
两个样本统计量n
如果要对两个总体有关参数的差异进行估计,就要研究来自这两个总体的所有可能样本相应统计量差异的抽样分布。n
两个样本均值差异
若从总体X1和总体X2中分别独立地抽取容量为n1和n2的样本,则由两个样本均值之差X1-X2的所有可能取值形成的概率分布称为两个样本均值差异的抽样分布。n
设总体X1和总体X2的均值分别为μ1和μ2,标准差分别为σ1和σ2,则两个样本均值之差X1-X2的抽样分布可概括为以下两种情况:n
(1)若总体X1-N(μ1,),总体X2-N(μ2,),则
X1-X2-N(μ1-μ2,)n
(2)若两个总体都是非正态总体,当两个样本容量n1和n2都足够大时,依据中心极限定理,X1-X2分别近似服从正态分布,则
X1-X2-N(μ1-μ2,)n两个样本比例差异
若从总体X1和总体X2中分别独立地抽取容量为n1和n2的样本,则由两个样本比例之差p1 − p2的所有可能取值形成的概率分布,称为两个样本比例差异的抽样分布。n
设两个总体的比例分别为P1和P2,当两个样本容量n1和n2都足够大时,根据中心极限定理,p1和p2分别近似服从正态分布,则有n
p1-p2-N(P1-P2,)
定理
- 从总体中随机抽取容量为n的一切可能个样本的平均数之平均数,等于总体的平均数,即E(x) = μ,(E为平均的符号,x为样本的平均数,μ为总体的平均数)。n容量为n的样本平均数在抽样分布上的标准差,等于总体标准差除以n的方根,即σx = σ/,(σx为平均数抽样分布的标准差,σ为总体标准差,n为样本容量。)n从正态总体中,随机抽取的容量为n的一切可能样本平均数的分布也呈正态分布。n虽然总体不是正态分布,如果样本容量较大,反映总体μ和σ的样本平均数的抽样分布,也接近于正态分布。
与样本分布和总体分布的区别n
统计中用随机变量X的取值范围及其取值概率的序列来描述这个随机变量,称之为随机变量X的概率分布。如果我们知道随机变量X的取值范围及其取值概率的序列,就可以用某种函数来表述X取值小于某个值的概率,即为分布函数:F(X)=P(X≤z)。
抽样分布指样本统计量的概率分布。采用同样的抽样方法和同等的样本量,从同一个总体中可以抽取出许许多多不同的样本,每个样本计算出的样本统计量的值也是不同的。样本统计量也是随机变量,抽样分布则是样本统计量的取值范围及其概率。仍以工业企业为例,我们设计了一个抽样方案并确定了样本量,这时可能抽取的样本是众多的,每抽取一个样本就可以计算出一个企业平均销售收入Xi,所有可能Xi形成的分布就是抽样分布。例中,样本统计量Xi为随机变量,抽样分布是Xi的概率分布。n
例如,一个由N家工业企业组成的总体,X为销售收入。将总体所有企业的销售收入按大小顺序排队,累计出总体中销售收入小于某值x的企业数量并除以总体企业总数N,就可得到总体中销售收入小于x的企业的频率,也即抽取一个销售收入小于x的企业的概率。此频率或概率随着x值不同而变化形成一个序列,形成了销售收入X的概率分布。n
总体分布
在总体中X的取值范围及其概率。n
样本分布
在样本中X的取值范围及其概率。上例中,如果抽取n个企业作为样本,我们同样可以用这n个销售收入的取值范围及其概率描述其分布,也即样本分布。样本分布也称为经验分布,随着样本容量n的逐渐增大,样本分布逐渐接近总体分布。nn
研究概率分布对于抽样调查是十分重要的,因为只有知道概率分布,才能够利用抽样技术推断抽样误差。现实中,总体的分布状况通常是未知的,但我们也无需知道总体分布,而只需知道抽样分布。